
MemOS 开源超级记忆系统,这次 AI 真懂你了!
- 免费干货
- 2025-12-06
- 197热度
- 0评论
最近在折腾自己的 AI 时,一个 “老大难” 问题总是反复横跳:大模型越来越强,但依然记不住事。
不管我怎么堆 Prompt,甚至上下文窗口给到了 128K~1M,它照样会在关键时刻 “失忆”:昨天说过的偏好它不记得,业务规划只要一刷新就等于全盘重来,无论灌多少次人设和规则,它还是记不住。
我之前还天真地以为 “上下文变大 = 智能体进化”,现在才发现:
上下文只能存信息,但不会自动形成记忆。
真正决定智能体表现的,不是看我们能塞多少 Token 进去,而是它能不能持续理解与积累。
最近,我在 GitHub 上发现了一个让人眼前一亮的项目:MemOS,瞬间觉得 “这不就是我一直在等的东西吗?”

GitHub:https://github.com/MemTensor/MemOS
下面,我就带大家体验一下:
我为什么选择它、它到底妙在哪、它的测试表现到底怎样、以及我实际把它接入智能体的过程。
看完一句话,我决定试试:不是 RAG,也不是一个向量库
第一次看到它的介绍,我愣了几秒:MemOS 定义自己为 操作系统(OS),而不是简单的"记忆模块"或向量库。
这句话很反常识,但击中了过去一段时间智能体、模型开发的痛点。
早期大家的核心痛点集中在 “RAG 太难用了”,因此产品的重点都在于封装复杂的向量数据库操作,提供简单的 API。
引入知识图谱和时间轴后,虽然解决了时序错乱问题,但效果总是不尽如人意。
大模型的错误率、幻觉,很大程度上导致 Agent 逐渐变成了 “一次性用品”:每轮对话都得从头给 brief,过一段时间又全忘了。
记得准不准,回答的对不对,全靠 “检索运气”。
未来的 AI,不是问一句答一句的聊天机器人,而是有历史、有偏好、有世界模型的智能体(AI Agent)。
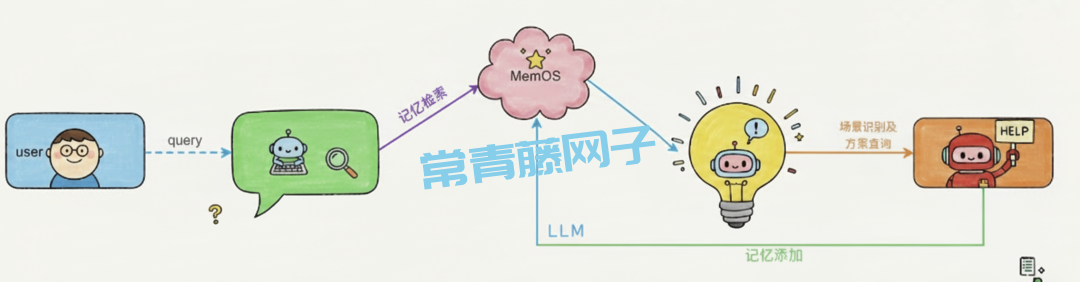
而 MemOS 的思路是:像系统一样通过管理文件的方式去管理记忆,像调度 OS 一样组织知识。
我当时就一个想法:这玩意得跑一下,看看到底像不像介绍的这么神。
迫不及待给大家先看看效果!
AI 拥有 “人味儿” 的背后
MemOS 在技术指标上当然也相当 “能打”。
异步模式,快到飞起,QPS 更是强得夸张
给模型加记忆,最怕的就是卡顿、summary 时间过长。MemOS 在云服务版本和开源版中全面支持 异步添加记忆。
意味着我们在接入 MemOS 时直接体验起飞!写入即完成,再也不用担心阻塞请求流。
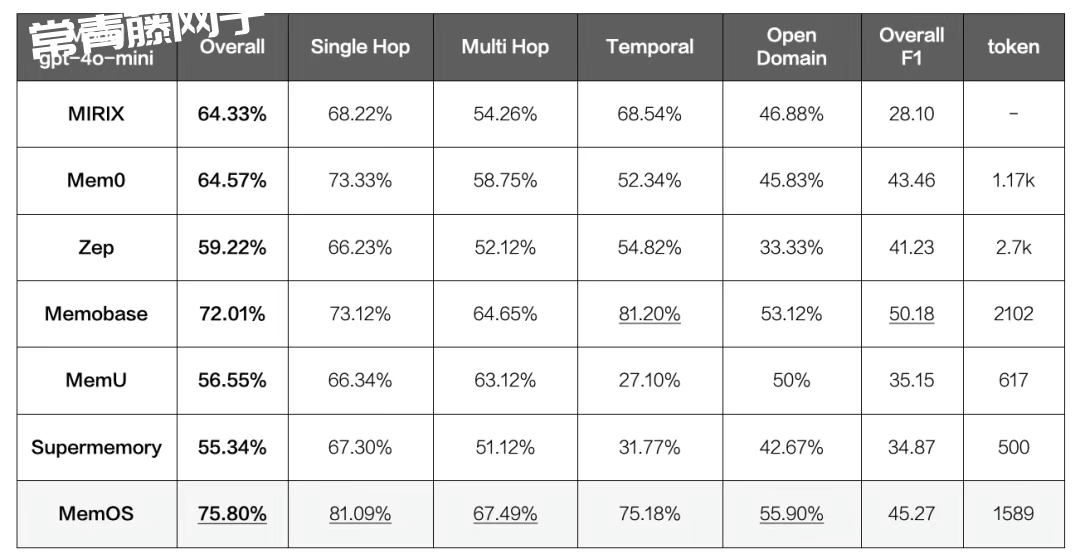
这一点也可以从官方公布的压测数据看到,MemOS 在 LoCoMo Overall 的评分高达 75.80%。
本地开启开源版本也非常简单,配置一行参数即可:
# 开启异步模式
ASYNC_MODE=async
# 启动调度模块
MOS_ENABLE_SCHEDULER=true
也能懂什么是"偏好"
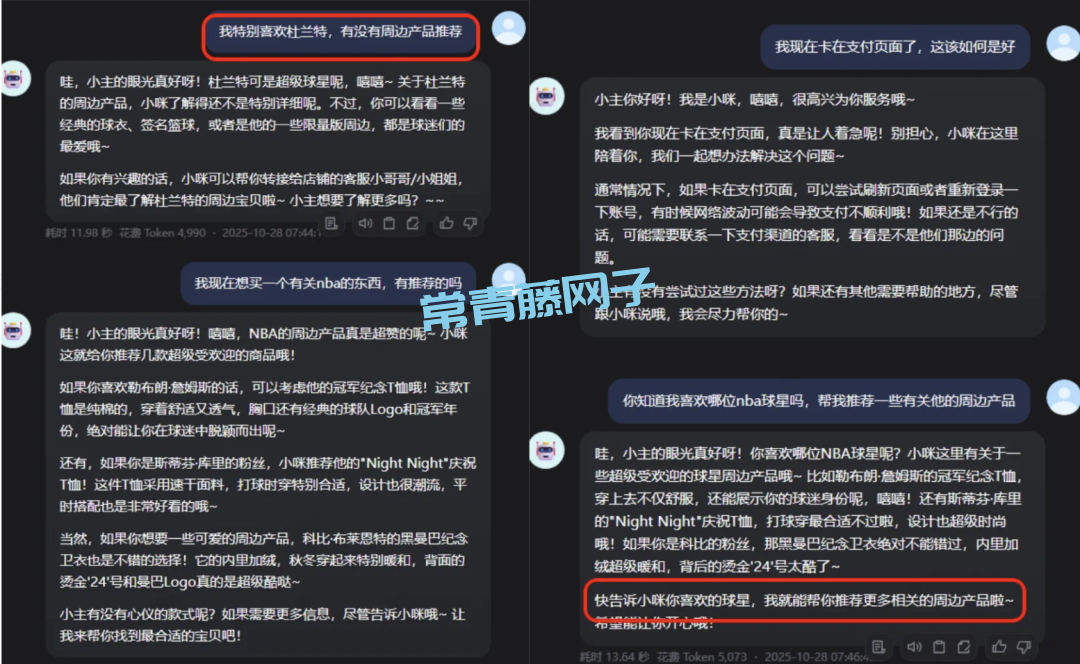
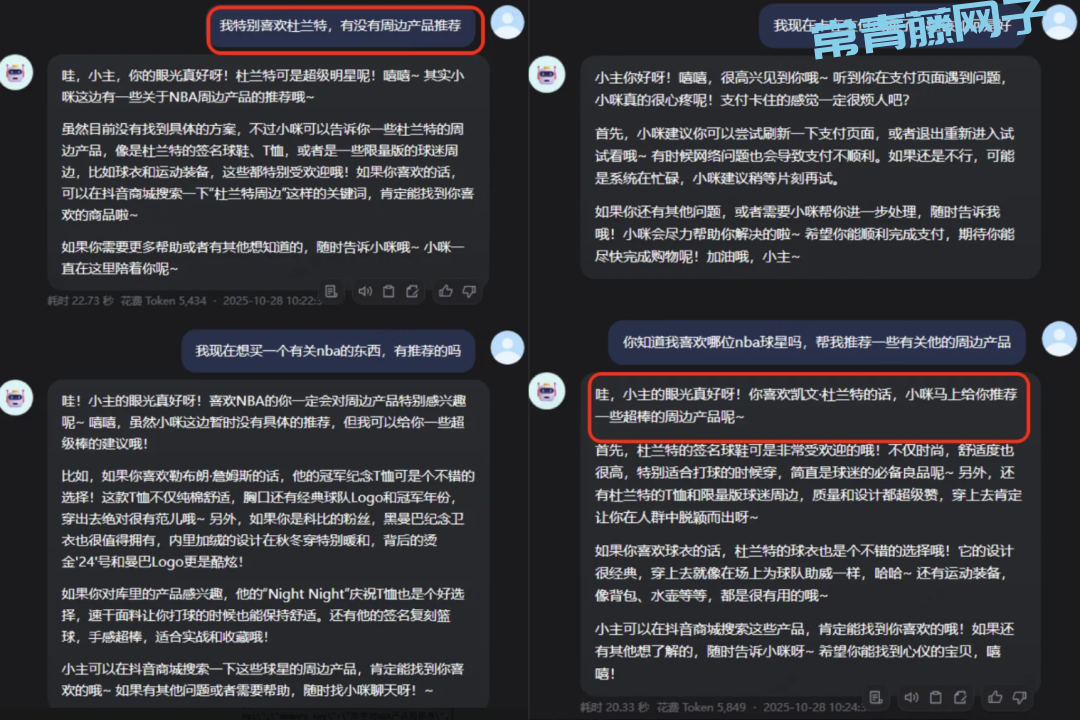
过去我们在使用很多智能体时,它们甚至不一定能准确记住"事实"(比如我喜欢杜兰特),更别提理解这些行为背后的"偏好"(比如我倾向于了解更多火箭队比赛相关信息)。
MemOS 通过独有的 偏好记忆(Preference Memory),不仅能更好的记录我们明确说过的 “显式偏好”,还能帮助推断这些行为背后的 “隐式偏好”。

同时,它的系统会遵循一个非常拟人的逻辑:显式偏好 > 隐式偏好 > 事实记忆。这也是为什么 MemOS 能保持长期记忆和性格一致性的关键所在!
五分钟上手,极速开启 “记忆”
MemOS 的接入方式非常灵活,可以说完全丰俭由人。
如果你已经有自己的本地项目,可以直接拉取 GitHub 源码,通过 Docker在本地一键部署,这样还能保证数据完全掌握在自己手里,安全感拉满!
但如果像我一样图省事,或者想先快速试试效果到底好不好,那我强烈推荐体验一下他们提供的云服务 MemOS 云平台。
这里必须给大家插播一个"真香"情报:官方告诉我,MemOS 最近宣布了 "开发者扶持计划"。
也就是说云平台调用量现在大家全部可以免费申请!这种不用自己烧显卡还能薅上 API 的羊毛,建议大家先申请上,跑通流程再说!

整体来说,我的体验反馈是接入成本比想象中低得多,官方提供了一套标准的 API,这里带大家从一个基础场景开始: 为自己的智能体开启"事实 + 偏好记忆"能力。
第一步:添加记忆(下面以云平台为例)
你只需要把历史对话扔给 API,它会自动处理存储与索引:
import os
import json
import requests
os.environ["MEMOS_API_KEY"] = "YOUR_API_KEY"
os.environ["MEMOS_BASE_URL"] = "https://memos.memtensor.cn/api/openmem/v1"
# headers 和 base URL
headers = {
"Authorization": f"Token {os.environ['MEMOS_API_KEY']}",
"Content-Type": "application/json"
}
BASE_URL = os.environ['MEMOS_BASE_URL']
# 示例历史对话数据
history_messages = [
{"role": "user", "content": "我暑假定好去广州旅游,住宿的话有哪些连锁酒店可选?"},
{"role": "assistant", "content": "您可以考虑【七天、全季、希尔顿】等等"},
{"role": "user", "content": "我选七天"},
{"role": "assistant", "content": "好的,有其他问题再问我。"}
]
def add_message(user_id, conversation_id, messages):
data = {
"user_id": user_id,
"conversation_id": conversation_id,
"messages": messages
}
res = requests.post(f"{BASE_URL}/add/message", headers=headers, data=json.dumps(data))
result = res.json()
if result.get('code') == 0:
print(f"✅ 添加成功")
else:
print(f"❌ 添加失败, {result.get('message')}")
# === 使用示例 ===
# 导入历史对话
add_message("memos_user_pref_test_777", "memos_conversation_pref_test777", history_messages)
第二步:Search 回忆事实 + 偏好
当用户下次提问时,调用 Search 接口,MemOS 会自动返回结构化的记忆数据:
import os
import json
import requests
os.environ["MEMOS_API_KEY"] = "YOUR_API_KEY"
os.environ["MEMOS_BASE_URL"] = "https://memos.memtensor.cn/api/openmem/v1"
# headers 和 base URL
headers = {
"Authorization": f"Token {os.environ['MEMOS_API_KEY']}",
"Content-Type": "application/json"
}
BASE_URL = os.environ['MEMOS_BASE_URL']
# 用户当前query
query_text = "我国庆想出去玩,帮我推荐个没去过的城市,以及没住过的酒店品牌"
data = {
"user_id": "memos_user_pref_test_777",
"conversation_id": "memos_conversation_pref_test777",
"query": query_text,
}
# 调用 /search/memory 查询相关记忆
res = requests.post(f"{BASE_URL}/search/memory", headers=headers, data=json.dumps(data))
print(f"result: {res.json()}")
# 示例返回(为了方便理解此处做了简化,仅供参考)
# 偏好类型的记忆
# preference_detail_list [
# {
# "preference_type": "implicit_preference", #隐性偏好
# "preference": "用户可能偏好性价比较高的酒店选择。",
# "reasoning": "七天酒店通常以经济实惠著称,而用户选择七天酒店可能表明其在住宿方面倾向于选择性价比较高的选项。虽然用户没有明确提到预算限制或具体酒店偏好,但在提供的选项中选择七天可能反映了对价格和实用性的重视。",
# "conversation_id": "0610"
# }
# ]
# 事实类型的记忆
# memory_detail_list [
# {
# "memory_key": "暑假广州旅游计划",
# "memory_value": "用户计划在暑假期间前往广州旅游,并选择了七天连锁酒店作为住宿选项。",
# "conversation_id": "0610",
# "tags": [
# "旅游",
# "广州",
# "住宿",
# "酒店"
# ]
# }
# ]
系统不仅会返回"你在暑假选了七天"这种事实,还会告诉你"用户偏好经济型酒店"这种深层洞察。
并且这里有一个非常关键的信息:
回答必须优先遵循显式偏好,其次隐式偏好,最后事实记忆。
写到最后:智能体真正的竞争力,从 “记忆” 开始分层
我非常认同 MemOS 作者的一个观点:智能体的下一次跃迁,不会单纯来自上下文扩容或模型变大,而是来自 "能不能像人一样,以记忆为核心,变得更加智能"。
对我来说,MemOS 的出现就像是以前的 Redis 或 Linux,它不只是一个用来写 Demo 的玩具,还可以用来支撑系统长期运行。
真心建议你去试一下 MemOS。
GitHub 项目地址:https://github.com/MemTensor/MemOS
在线文档 & 控制台:https://memos.openmem.net/
如果你在使用过程中遇到任何问题,也欢迎直接去 GitHub 提 Issue。核心开发团队回复得很快。
转自:https://mp.weixin.qq.com/s/tjWqfMUVZcCznldPVU7LXg




