
CloudFlare 如何让合法搜索引擎蜘蛛爬虫正常抓取
- 服务器知识
- 2023-09-06
- 314热度
- 0评论
很多站长们都有个普遍的误解那就是使用 CloudFlare 会影响搜索引擎爬虫的正常抓取,这个明月经过实际体验后发现根本不存在这个问题的,先不说 CloudFlare 自己的“合法 Bot”大数据的精准度,单就 CloudFlare 强大的 WAF 规则就不允许这种情况的发生,所以今天明月给大家分享一下 CloudFlare 如何让合法搜索引擎蜘蛛爬虫正常抓取。注意,是合法的,仿冒的或者垃圾爬虫不在这个范围内哦!
首先说明的是 CloudFlare 默认情况下是会对所有来访请求以及频率进行过滤的,如果这期间搜索引擎蜘蛛爬虫来访频繁是会遭到 CloudFlare 的自动拦截过滤的,这也是很多站长们误解的主要因素之一,所以建议大家使用 CloudFlare 后第一时间要创建一个免费的 WAF 来给所有的搜索引擎蜘蛛爬虫放行(CloudFlare 后台——【安全性】——【WAF】里免费版可以创建 5 条 WAF,对于我们普通博客站点来说足够用了),具体如下截图:
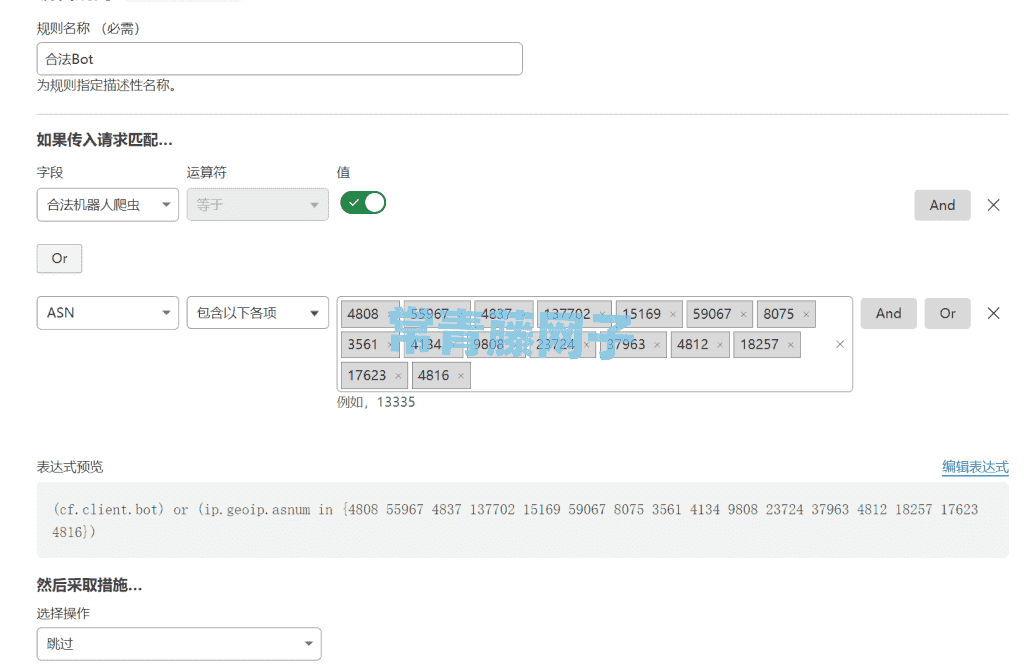

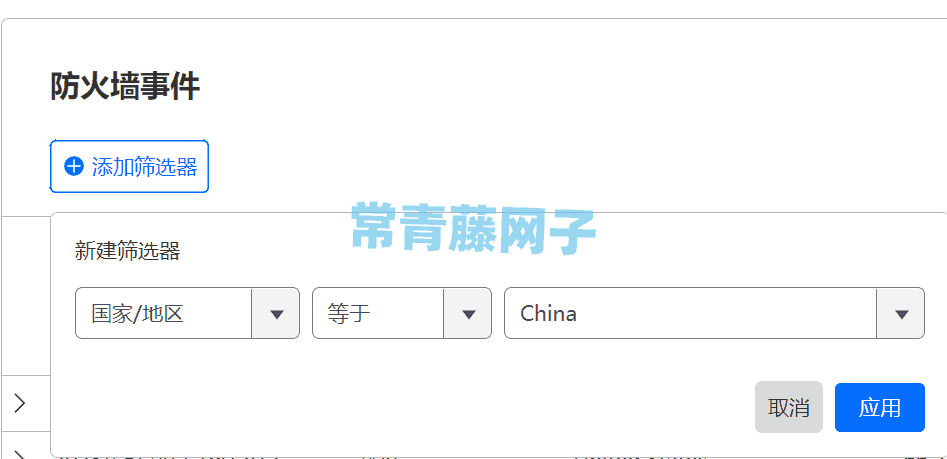
等待一会儿后就可以在 CloudFlare 后台【安全性】——【事件】里来观察放行搜索引擎蜘蛛爬虫的记录了,可以借助【事件】里的【添加筛选器】来单独查看来自国内(China)的爬虫,具体如下图所示:
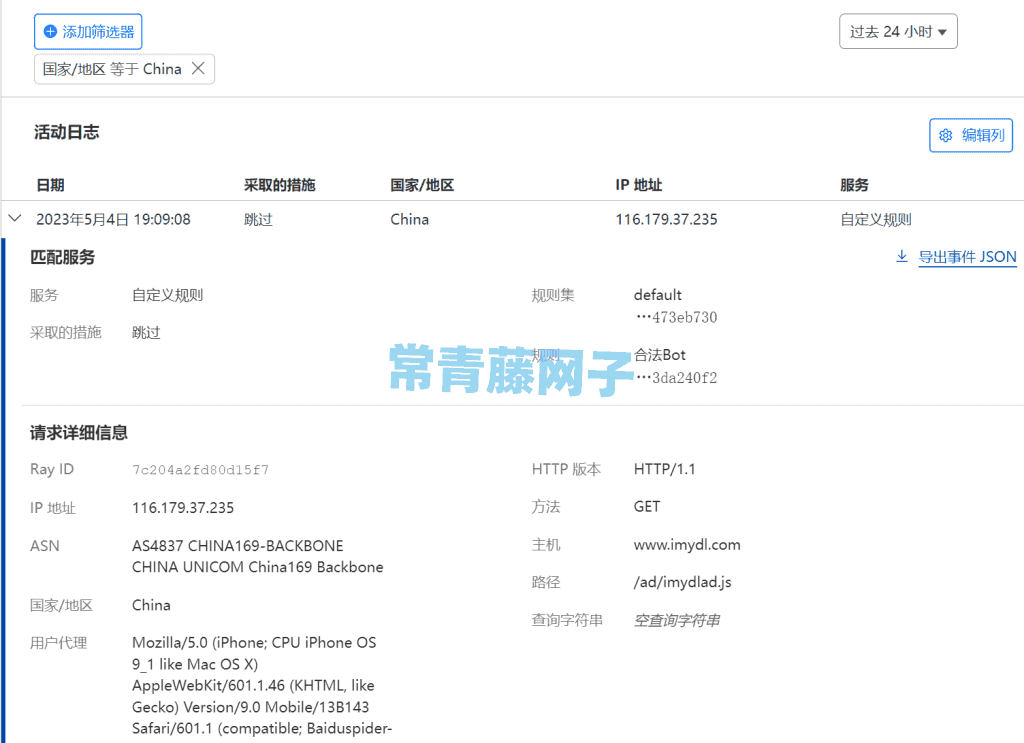
然后点击任意一个记录即可看到是哪个搜索引擎蜘蛛爬虫来访了,如下图所示,百度搜索引擎蜘蛛爬虫正在来访和抓取,CloudFlare 给放行并记录了:
当然,也可以利用【事件】里的【添加筛选器】根据更多条件查看搜索引擎蜘蛛爬虫来访的记录,比如用【用户代理】来查看所有谷歌爬虫等的记录等等,具体大家慢慢研究吧!
本文转自明月登楼的博客




