
VibeVoice 解放配音员?这个微软开源的AI模型能生成超长音频
- 工具收集
- 2025-10-16
- 132热度
- 0评论
项目简介
在语音合成领域,生成语音的自然度和长度一直是一对难以调和的矛盾。多数模型擅长生成短句,但面对长篇内容时,会出现音质下降、语调单调或前后不一致的问题,限制了其在有声书、播客等场景的深度应用。
VibeVoice作为一个开源文本转语音模型,其设计目标就是突破这一限制。它的核心能力体现在能一次性生成长达90分钟的连贯语音,并在此过程中稳定保持多个角色的音色特征。这意味着它可以直接用于生成包含多人物对话的完整章节内容。
这一能力的实现不依赖于复杂的后期处理,而是模型内在架构的革新。它通过更高效的方式理解文本语义并对应到声音特征,从而在源头确保了长文本生成的连贯性和表现力。这为音频内容的自动化生产提供了新的可能性。
食用指南
访问地址
传送门:https://microsoft.github.io/VibeVoice/
开源地址:https://github.com/microsoft/VibeVoice
试用地址(非官方):
https://huggingface.co/spaces/yasserrmd/VibeVoice

官网地址

开源地址
官方的项目页面有详细的模型介绍,有兴趣可以进去看一下,开源地址上面目前只有一些说明,暂时还没有提供代码。HF上面已经有模型权重可以下载了
我从HF上面找了一个可以使用的空间,但是这个空间不是微软官方的。所以并不能保证一定是长期有效的。
基础功能说明

工作界面

模型
有多种模型尺寸可以选择,官方的模型权重也都开源出来了,也可以放在本地部署使用,一般的家用电脑也就只能跑1.5B或者7B的尺寸,再大就不行了

说话人

说话人
说话人的数量可以调整,最多4个人,最少1个人,每个说话人的语言可以选择。中文语言目前看到有3个语音可以使用。英语的可选范围更广一些。

高级设置
此处保持默认就可以。

对话脚本
在对话内容的每一段的最前面,需要标注出Speaker对应的数字,这样AI会播放出对应说话人的声音。
操作与体验——单人说话

单人脚本
VibeVoice在语音的场景里面最长能支持到90分钟的对话,可以持续的输出长对话内容。
这边我们让AI随便生成了一些内容尝试,单人对话场景可以不标注Speaker。因为只有一个说话人,所以标注是非必要的。
 生成中
生成中
生成预计所需要的时间大概是60秒,但是实际生成大概是30秒不到。
模型方面我选择了1.5B的模型,看看适合本地部署的模型质量如何
 生成结束
生成结束
生成结束后可以直接在线试听效果,下方也会把本次试用的模型,生成的时间,所用到的所有参数以Log的形式呈现出来,方便回顾内容。
因为我选的是BGM版本的,所以人物刚开始说话会有一点小的BGM开场。
操作与体验——多人人说话
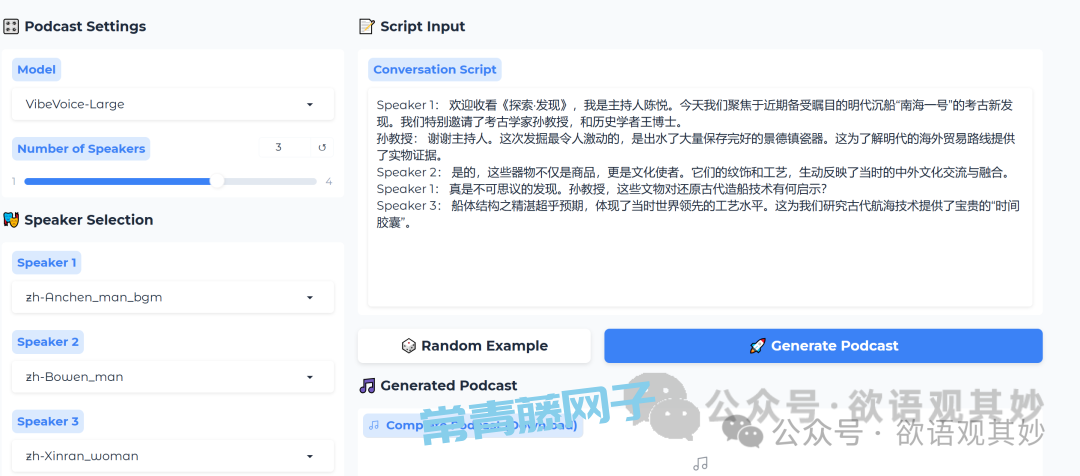
说话样例

生成结果
多人对话的时候,必须要标注Speak的数字,便于AI调用对应的语音,生成速度多人的比单人的会慢上不少,在文字数量差不多的情况下,生成时间多了大概10几秒的时间。
实际生成的过程中,还有时候会出现交替的时候有杂音的问题。就像生成图片一样,需要多抽卡几次才行。多人对话的视频比较容易出现这个类似Bug的问题。
写在最后
VibeVoice 的出现,标志着语音合成技术从生成短句向驾驭长篇叙事的重大跨越。其开源特性降低了使用门槛,而支持多达4名角色、90分钟超长对话的能力,则为其在有声书、播客、视频配音等领域的深度应用铺平了道路。尽管在多人对话的稳定性上仍有提升空间,但它无疑已经为我们提供了一个功能强大且充满潜力的工具。
对于开发者和技术爱好者而言,这是一个值得深入探索和部署的优质项目。对于普通用户,通过 Hugging Face 等平台提供的演示空间,也能轻松体验前沿 TTS 技术的魅力。随着模型的进一步优化和开源社区的持续贡献,VibeVoice 有望成为构建沉浸式音频内容的基石,推动 AI 语音合成进入一个全新的“长音频”时代。
转自:https://mp.weixin.qq.com/s/rc1GedDdB0TlHx2vJvpPpg




