
跨Cursor、Cline等多端通用长时记忆,Mem0-MCP一次设置,处处可用!
- 免费干货
- 2025-05-06
- 236热度
- 0评论
相信你也遇到和我一样的问题:
在Cursor中精心定义的项目规则,换到Windsurf就要重新配置。
在Claude中提取的完美提示词,到了CherryStudio又得从头再来。
每次换AI编程工具,都在大量重复同样的复制粘贴工作。
即便是同一客户端,同一个项目,不同窗口之间也需要提示相关的上下文内容。
究其原因,第一个是因为没有一个统一的记忆内容管理平台,可以做到随手即用。
第二个是因为LLM的致命缺陷:它们缺乏在会话之间或超出有限上下文窗口保留信息的能力。
即便是号称拥有数十万甚至数百万令牌的大上下文窗口,多次交互后,对话历史仍然会超出限制。
更糟是,随着上下文长度增加,AI对早期信息的注意力会急剧下降,出现大量的幻觉。
为了解决这个痛点,Mem0-MCP应运而生。
这个开源项目通过创建一个独立的记忆服务层,让你的编程偏好和项目知识可以在不同的AI工具和会话间之间共享。
mem0-mcp 是由 Mem0 团队开发的一个特定工具,利用 Mem0 服务 通过模型上下文协议 (MCP) 标准来记忆和管理编码偏好 。
当你教你的 AI 编码助手(比如 Cursor)你喜欢的注释风格、错误处理方式或项目结构时,它能够在不同的会话中记住这些偏好。
mem0-mcp 正是提供了一种构建这种记忆能力的方法 。允许 AI 助手持久化存储和检索用户的编码习惯和模式,使得 AI 的辅助更加个性化和高效。
核心优势
统一记忆中心
一次配置,多端使用
支持Cursor、Claude、Windsurf等多种工具
基于标准MCP协议,易于集成
智能记忆管理
自动提取和存储关键编程偏好
支持语义化搜索和检索
保留完整上下文信息
灵活部署架构
独立服务器进程
支持云原生部署
RESTful API接口
工作原理
Mem0-MCP通过三个核心API实现跨平台记忆:

1 . add_coding_preference:智能存储代码片段、配置和最佳实践
2 . get_all_coding_preferences:检索所有存储的编程偏好
3 . search_coding_preferences:语义化搜索相关记忆
Mem0 的核心在于其结合了大型语言模型 (LLM) 和向量存储技术 。
利用 LLM 从对话或数据中自动提取关键信息、事实或偏好 ,然后将这些信息转化为向量表示(嵌入),存储在向量数据库中。
向量化的表示使得可以通过语义相似性进行高效搜索,即使查询与存储的原文不完全匹配,也能找到相关的记忆 。
所以整体上Mem0 不仅仅是存储,它还能主动管理这些记忆,不管是后期的更新信息或合并相关的记忆片段都可以保持准确性 。
应用
这里一个实际的python案例为例:
我在CherryStudio中整理整个项目的开发规范,Mem0-MCP自动捕获并存储这些偏好。

回到Cursor或者Cline或者Claude中继续开发时,所有配置保留在记忆体当中,通过MCP直接可用调取并应用。
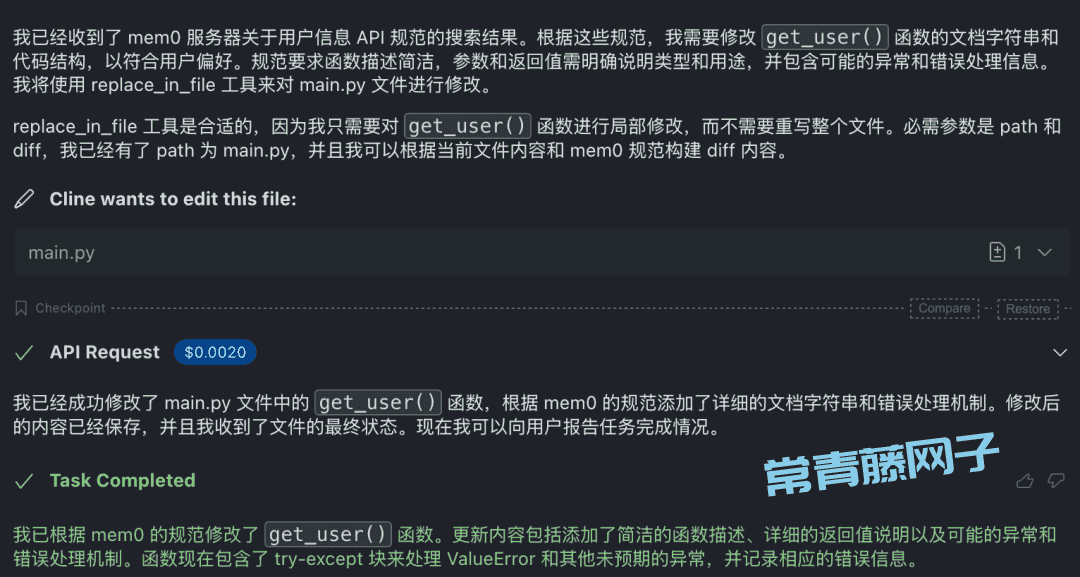
下图演示了将项目规范直接应用到一个具体的函数:

快速开始
MCP服务使用超级简单,安装和配置只需几步:
# 克隆仓库
git clone https://github.com/mem0ai/mem0-mcp.git
cd mem0-mcp
# 设置环境
uv venv
source .venv/bin/activate
uv pip install -e .
# 配置API密钥
echo "MEM0_API_KEY=your_key" > .env
# 启动服务
uv run main.py
接下来只需要在配置选项里面勾选SSE连接即可。
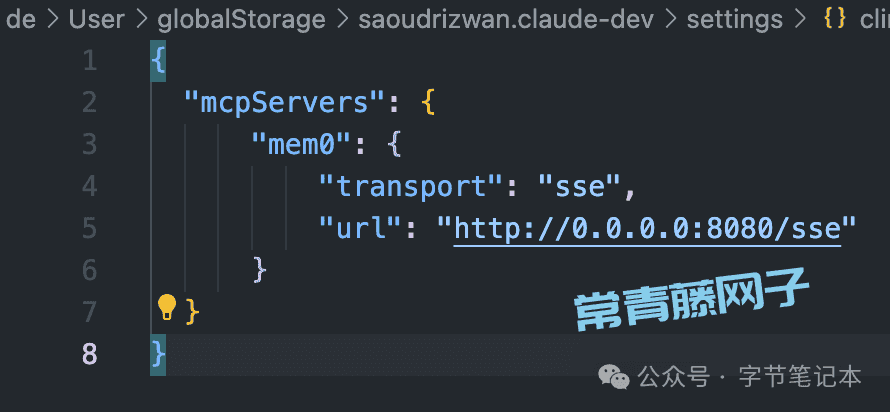
目前mem0云在线服务提供了相当大的免费额度,通过mem0官网我们就可以获得上述的key。
转自:https://mp.weixin.qq.com/s/s86N0a2cpymlQwDonIyZeQ




